 تويت
تويت
Machine Translation: Ingredients for Productive and Stable MT deployments - Part 2
 This is the second of three planned articles reporting on Machine Translation (MT) industry developments that emerged at the AMTA (Association for Machine Translation in the Americas) conference held in Honolulu, Hawaii, October 21-25, 2008. AMTA conferences are held in even-numbered years. In 2009, AMTA will also host the IAMT Summit conference summitxii.amtaweb.org. AMTA's founding goal is to bring together users, developers and researchers of MT. This format provides a unique opportunity for interaction between those communities, and to catch up on everything MT - from long term research developments to current deployments and products. This time, I draw on some additional sources as well as the conference to give some historical context, cover the current state of machine translation research, and see what researchers themselves are predicting for the next one to five years.
This is the second of three planned articles reporting on Machine Translation (MT) industry developments that emerged at the AMTA (Association for Machine Translation in the Americas) conference held in Honolulu, Hawaii, October 21-25, 2008. AMTA conferences are held in even-numbered years. In 2009, AMTA will also host the IAMT Summit conference summitxii.amtaweb.org. AMTA's founding goal is to bring together users, developers and researchers of MT. This format provides a unique opportunity for interaction between those communities, and to catch up on everything MT - from long term research developments to current deployments and products. This time, I draw on some additional sources as well as the conference to give some historical context, cover the current state of machine translation research, and see what researchers themselves are predicting for the next one to five years.
What is machine translation?
The Vauquois<SUP id=1_1>[1]</SUP> triangle was used in the linguistic rule-based era of machine translation to describe the complexity/ sophistication of approaches to machine translation, and also the evolution of those approaches. The first approach used was a direct lexical conversion between languages. Later efforts moved up the pyramid and introduced more complex processing, and also a modularization of the process into steps, beginning with analysis of the source language, transfer of information between the languages, and then generation of target language output. According to the model, each step up the triangle required greater effort in source language analysis and target language generation, but reduced the effort involved in conversion between languages. The pinnacle and ideal of the field (especially if you asked people in Artificial Intelligence) was a complete analysis of each sentence into an "interlingua" - a schema capable of representing all meaning expressable in any language in language-independent form.
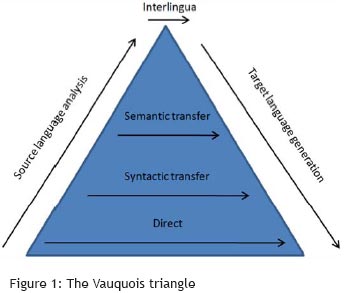 When statistical MT emerged, the Vauquois triangle did not seem relevant, and became largely a museum piece. But with the recent growth of syntactic statistical methods, I had a sense of déjà vu, followed by the vision of a new model that resembles a series of staircases.
When statistical MT emerged, the Vauquois triangle did not seem relevant, and became largely a museum piece. But with the recent growth of syntactic statistical methods, I had a sense of déjà vu, followed by the vision of a new model that resembles a series of staircases.
The differences between statistical and rule-based machine translation have been covered extensively elsewhere, so I will not describe them here. See, for example: http://en.wikipedia.org/wiki/Statistical_machine_translation or promotional whitepapers by statistical MT developers.
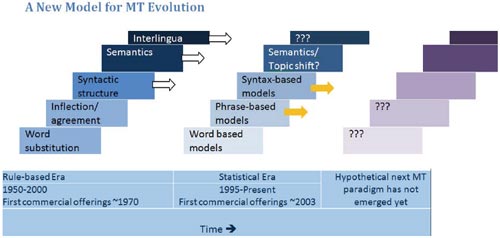
 There are still many established groups internationally doing research on linguistic rule-based machine translation, in the frameworks (steps) that have white arrows. There are also other data driven approaches, such as example-based machine translation, that emerged around the time of statistical MT, which are not represented in this model. But the growth in the MT research community since 1999 is largely in statistical methods. And that growth has been so fast since the early 2000s, that it now represents the overwhelming majority of researchers of MT.
There are still many established groups internationally doing research on linguistic rule-based machine translation, in the frameworks (steps) that have white arrows. There are also other data driven approaches, such as example-based machine translation, that emerged around the time of statistical MT, which are not represented in this model. But the growth in the MT research community since 1999 is largely in statistical methods. And that growth has been so fast since the early 2000s, that it now represents the overwhelming majority of researchers of MT.
As in the rule-based era, the statistical paradigm got started with word-based translation. The statistical MT community actually had exhausted and moved on from word-based statistical models before any such systems were commercialized, though there are open-source toolkits for word-based statistical machine translation that are used in teaching. Current primary research activity is in phrase-based statistical MT and syntax-based statistical MT. Phrase-based models of translation produced better output with less bilingual training data than the word-based models. Phrase-based statistical MT is now the dominant approach in research, and is well supported with academic courses, open-source toolkits, and an online community with the website www.statmt.com. Syntax based statistical MT is the growth area right now, and seeks to address weaknesses of the phrase-based approach in handling complex grammatical structure, and translation between languages with very different basic word order.
The world of MT made some great strides forward in moving to statistical methods. The convenient availability of large quantities of data for the major languages, and the ability to train translation systems automatically has led to rapid system development, and cost effective vocabulary and style adaptation that were expensive and slow with rule-based MT. Statistical models further manage to produce output that is much more fluent sounding than rule-based MT. But don't sell your shares of Systran just yet - rule-based MT, especially as a commercial product, has some advantages that are not eclipsed by statistical MT, particularly for translating into morphologically complex languages, in providing extensive dictionary-based customization capabilities, and providing translation capability for language pairs or text types where no bilingual training data exists. And the rule-based MT developers are not sitting idle during the statistical revolution. Their efforts to hybridize are yielding very interesting results, and have ensured that the " horse race" between the generations of MT is not over yet.
The next paradigm shift
In a second marriage, the early years are spent in happy relief from the problems of the prior marriage. And this is where the research community is with statistical machine translation, happy to be free of the drudgery of manual rule development. And the community of users is also finding that the current advances bring machine translation closer to its potential as a mainstream business tool. But statistical approaches don't solve every problem from the rule-based era, and even introduce some new ones. The hypothesis of another paradigm shift, and new "era" of machine translation 5 or 15 years in the future is my speculation that eventually a researcher, perhaps from another field entirely, will have an "aha" moment that shows the way to the next era of machine translation. And that generation can tackle the problems that still remain on the prior generations' "someday/maybe" project list.
Current focus, next step
Researchers looking for the next increment of improvement in translation accuracy are currently exploring ways to incorporate syntactic information into translation models and language models. This exploration began in about 2003 with some unsuccessful efforts, gradually had some success and has now gained popularity as a research pursuit. In the research tracks at the AMTA and EMNLP (empirical methods in natural language processing) conferences in October 2008, there were 14 papers reporting advances in the phrase-based framework and 10 in various syntax-based frameworks. A recent survey by Dr. Daniel Marcu of USC/ISI and Language Weaver polled his colleagues in the research community about the best and worst ideas in the history of natural language processing<SUP id=2_2>[2]</SUP>. The responses, which also include predictions on what will work well in the future, suggeste that syntax-based methods for statistical MT will continue to be an area of significant focus through about 2013. The same survey suggested that semantics, robust handling of different topics and topic shift, and handling of discourse structure, will begin to see results around 2018.
The National Institute of Standards and Technology (NIST) conducted a series of workshops in 2006 with the prominent researchers in machine translation and natural language processing. They were asked to identify the biggest challenges for the field, and the technological advances necessary to achieve the field's significant long term research goals<SUP id=3_3>[3]</SUP>. One of the long term goals for machine translation was to be able to translate text with roughly the skill of a human. Some researchers believed that in order to do this, computers must be able to "understand" language. That group might put "interlingua", or something like it, again on the top stair step for the statistical era. But many researchers don't buy into the notion that successful translation has to resemble the human translation process, and are wary of a return to the old days of AI, in which pursuit of human-like function was pursued without attention to system performance or scaling up to real world problems.
In the opening paragraph of this article, I emphasized that machine translation translates sentences. A challenge identified by the NIST survey, which has sometimes been brought up by customers, is the inability of current MT systems to consider information from outside the sentence being translated. This emerged as a problem in the rule-based MT era, did not get much attention then, and has not been a topic of much research in the statistical era either. The need to draw on information from outside the sentence was identified in the NIST study as a key enabler for the long term goals of machine translation research. The ability to draw on a larger information resource, whether from the surrounding context, or perhaps world knowledge, could be the innovation that defines the next era of MT research.
When statistical machine translation emerged as an idea, it came from researchers working on speech recognition and signal processing. At the time, this seemed like an absurd leap to the linguistic rule-based MT community. It is conceivable that the next paradigm shift will similarly take the statistical MT research community by surprise.
Meanwhile back in the commercial world
Note that statistical machine translation has reached the deployable stage in two commercially licensable software products (Language Weaver and IBM), one free online service (Google), and one in-house system (Microsoft). A new company, Asia Online appears to be on the point of having statistical MT offerings, and there are probably others that haven't come to my attention yet. But the majority of commercially available MT software that is doing real work out in the world is still linguistic rule-based. Examples include Systran, SDL, LEC, ProMT, Linguatec, WordMagic, Apptek, Sakhr, and many Japanese, Chinese and Korean MT systems that are mostly available in those regions. As I hinted earlier, the rule-based MT developers are starting to get comfortable with statistical thinking, and are finding ways to combine the strengths of the new approaches with the systems and resources they have built up over many decades. And this work in industry is another component of the MT research landscape.
Hybridization
Many observers of the MT community believe that the best results will come from hybridization - the combination of resources and techniques from the rule-based and statistics-based approaches. At least two genuine hybrid approaches have emerged:
Who's winning?
The adoption of the BLEU metric by researchers and their funders, together the regular public MT evaluations conducted by NIST<SUP id=5_5>[5]</SUP> (the U.S. National Institute of Technology and Standards) have given MT evaluations the flavor of a horserace. Prospective customers of MT may feel they are best served by reviewing these evaluations and see "who won". But the real story is not that simple. The NIST evaluations, and the BLEU-score metric, have been very powerful drivers of progress in the research community, and perhaps even explain some of the growth of the cohort of researchers in this area. But BLEU scores and NIST evaluation results are not necessarily helpful in selecting an MT system. There are several reasons for this.
DARPA's Agenda
First, the vast majority of the evaluations conducted by NIST and DARPA over the past 8 years have been on translation of Arabic and Chinese newswire texts into English. This choice mirrors the military/intelligence challenge that is being targeted with research dollars - the overwhelming volume of foreign language materials that must be scanned - but more on that next month when I talk about U.S. Government use of MT!
Research vs. commercial systems
The MT systems used in the NIST evaluations are not commercially available for sale or for use online. The goal in the competitive evaluations is to achieve the highest evaluation score, and for this, many research groups take rather extreme measures. The test involves translating 1,000 sentences which are issued to the participants and must be returned translated. In 2005, Google's Franz Och reported that for the unrestricted data track, they dedicated one computer to each sentence, and allowed the translation search process to run for a week on each one.
Translation systems that are available commercially or free online, have been heavily optimized for speed and efficiency to produce translations in real time. The path from research advances made in an environment of unrestricted resources, to deployable software, can be as little as 6 months or a year.
BLEU favors phrase-based SMT systems
The BLEU metric, first proposed in 2001 by the IBM statistical MT research group, is an automated measure of similarity between two texts. In this case, it measures the similarity between a machine translated text and a human translated "reference". The similarities it captures are words and word-sequences that appear in both texts. Because human translations often differ from each other in word choice, it is common to use the BLEU score to compare an MT output to 4 reference translations from different human translators. In the early 2000s, BLEU was a blessing. It enabled researchers and their funders to instantly evaluate system performance and progress. And in that early phase of statistical MT research, BLEU scores appeared to correlate strongly with human judgments on translation accuracy.
But as statistical machine translation systems got better, and as BLEU was applied to rule-based systems for comparison, some limitations appeared. As Joe Olive, Program Manager of the DARPA GALE program acknowledged at the AMTA conference in 2006<SUP id=6_6>[6]</SUP>, the BLEU score is "not sensitive to comprehensibility or accuracy" and "favors SMT". This growing awareness motivated the DARPA program to move to a different evaluation metric using human editors. The new metric, called HTER (Human Translation Error Rate) has monolingual editors compare a human reference translation with a machine translated sentence. The editor then makes the smallest number of modifications to get the machine translated sentence to mean the same thing as the human translated sentence without attention to style. Those modifications are counted, and the error rate is the average number of words per hundred that were corrected.
Other vagaries of BLEU
A BLEU score is not a generalized measure of system goodness, but a measure of how well a translation system translated a particular text. This is useful in comparing different MT systems only if, as in the case of NIST, all the translation systems have translated exactly the same text. Performance on other texts may vary significantly.
One to five year outlook
Are we there yet?
This is a very exciting time in machine translation. There is an unprecedented number of energetic, highly qualified and competitive research groups who are also producing deployable machine translation software. Developments in the research arena move pretty quickly into real usable translation systems. And the fact that there are several comparably talented groups means that the competition is intense. This is very good for users and prospective users of machine translation, but it will be worth your while to help the research community to focus on your problems.
Earlier I mentioned some abstract programmatic goals of machine translation research, such as adding semantic processing, and raising BLEU scores on Arabic news translations. But real world applications often require effort on problems that are not salient to the research community. Commercial translation services companies and translation clients might be happy if machine translation could deliver 10% productivity increases every 2-5 years in their operations. The U.S. Marine Corps wants the "Star Trek Universal Translator" for every soldier in the field. It's not clear that semantics or BLEU scores are the pptlimiting factors for either of those applications. User goal needs to be explored with developers and researchers, to make sure that R&D efforts will yield progress in practice. The research world needs input, and funding, to energize them, and attract talent and resources to those areas.
In the U.S., the majority of research funding over the last 8 years has come from DARPA in two 5-year research programs, first TIDES (2000-2005), and then GALE (2006-2010), which is now in its third year. These programs have funded a number of research groups to pursue the intelligence agenda for MT: bring machine translation for key languages - Arabic and Chinese into English - to the level where English speaking analysts can scan and gather information from foreign language news (this is a gross oversimplification of the goals, but it is a reasonable summary of what has been achieved). For Arabic-to-English they have certainly succeeded, and the performance of research MT systems lags only slightly behind human first-draft translations. Chinese has proven much more difficult, and the fact that the research campaigns on Arabic and Chinese have been waged with the same algorithms and the comparable amounts of training data, has demonstrated more powerfully that some language pair directions are much harder than others.
Efforts to deploy machine translation often expose areas where companion technologies or combinations need some research effort. But there is not much funding for technology transition or solutions involving MT, and these areas are weak links in putting machine translation to work.
What can you do affect the process?
Show up
Participate in the conference events of the IAMT (International Association for Machine Translation) regional associations: AMTA (www.amtaweb.org), AAMT (www.aamt.info) and EAMT (www.eamt.org). The associations' founding goal was to bring together users, developers and researchers. This provides a forum where you really can get the attention of researchers and developers to hear about their plans and tell them your needs (without just inviting a barrage of sales information.)
Think through and articulate requirements
The research community can pursue general theoretical goals and advancements, or they can pursue real performance targets and capabilities. Some people (including me) complain that research is overly concerned with abstract performance targets given by DARPA, which may not move the technology toward solving real-world translation problems. But DARPA is one of the few places that have articulated clear goals and problems that the research community can tackle. Prospective users of machine translation often aren't clear about the problem they are trying to solve with automation. And so the market has never sent very clear signals to the research community (or to developers).
Be an objective shopper
If you are intrigued by the details of technology, you may find that some approaches more intellectually appealing. But long term happiness with MT will depend on the technology's ability to perform, and the vendor's commitment to support you. Do a thorough evaluation asking questions like, "How does this system perform on my text now?" and "Can it be brought to the level that I need it?", and "How happy are other customers?"
Put MT to work and give feedback
Become a demanding customer. Machine Translation needs real work in order to continue its progress toward becoming a valuable, trusted, mainstream business tool. When software users get frustrated, they most often complain to colleagues. It is so important to tell software developers what you like and don't like. But be persistent, they may not get it the first time. Your comments to MT developers, research funders, and the groups who do evaluation really can impact the priorities and direction of research.
Closing Thought
This article ended up being difficult to write because there is so much activity, and so many intertwining forces at work on MT research today. I have probably failed to mention your biggest concern, favorite research topic or group, or address the question you consider most obvious and pressing. Please email me gerbl@pacbell.net.
Errata
The URL was omitted from last month's article linking to presentations from the Recipes for Success workshop: http://www.amtaweb.org/AMTA2008.html Scroll down just below the sponsor logos.
Author Bio
Laurie Gerber has worked in the field of machine translation for over 20 years, including system development, research, and [COLOR=blue! important][COLOR=blue! important]business [COLOR=blue! important]development[/COLOR][/COLOR][/COLOR]. Throughout this time, users and usability have been a defining interest. Laurie became an independent consultant in April 2008 in order to help user organizations create successes with machine translation and other language technology.
Laurie has been active in the machine translation professional community since 1992 and is currently treasurer of the Association for Machine Translation in the Americas, and President of the International Association for Machine Translation. http://www.amtaweb.org
Notes
ClientSide News Magazine - www.clientsidenews.com
By Laurie Gerber,
treasurer, Association for Machine Translation in the Americas president,
International Association for Machine Translation
==========
treasurer, Association for Machine Translation in the Americas president,
International Association for Machine Translation
==========
This is the second of three planned articles reporting on Machine Translation (MT) industry developments that emerged at the AMTA (Association for Machine Translation in the Americas) conference held in Honolulu, Hawaii, October 21-25, 2008. AMTA conferences are held in even-numbered years. In 2009, AMTA will also host the IAMT Summit conference summitxii.amtaweb.org. AMTA's founding goal is to bring together users, developers and researchers of MT. This format provides a unique opportunity for interaction between those communities, and to catch up on everything MT - from long term research developments to current deployments and products. This time, I draw on some additional sources as well as the conference to give some historical context, cover the current state of machine translation research, and see what researchers themselves are predicting for the next one to five years.What is machine translation?
Before we dive into current trends in Machine Translation research, I'd like to clarify the part of the translation problem that is usually addressed by MT research - the fully-automated translation of digitized text sentences from one language to another. Processes or "software solutions" that incorporate MT may involve other research-worthy steps just to get the input into digitized text form. For example speech translation systems entail speech recognition to get the audio signal into digitized text form, and possibly conversion of the translated text back into an audio signal via text to speech software. Similarly, translating printed or handwritten paper documents entails an OCR or handwriting recognition step. For the present, we will set those problems aside, to look at research progress, current and predicted, in machine translation proper: translation of electronic text from one language into another.
Model for MT progress in the rule-based eraThe Vauquois<SUP id=1_1>[1]</SUP> triangle was used in the linguistic rule-based era of machine translation to describe the complexity/ sophistication of approaches to machine translation, and also the evolution of those approaches. The first approach used was a direct lexical conversion between languages. Later efforts moved up the pyramid and introduced more complex processing, and also a modularization of the process into steps, beginning with analysis of the source language, transfer of information between the languages, and then generation of target language output. According to the model, each step up the triangle required greater effort in source language analysis and target language generation, but reduced the effort involved in conversion between languages. The pinnacle and ideal of the field (especially if you asked people in Artificial Intelligence) was a complete analysis of each sentence into an "interlingua" - a schema capable of representing all meaning expressable in any language in language-independent form.
The differences between statistical and rule-based machine translation have been covered extensively elsewhere, so I will not describe them here. See, for example: http://en.wikipedia.org/wiki/Statistical_machine_translation or promotional whitepapers by statistical MT developers.
As in the rule-based era, the statistical paradigm got started with word-based translation. The statistical MT community actually had exhausted and moved on from word-based statistical models before any such systems were commercialized, though there are open-source toolkits for word-based statistical machine translation that are used in teaching. Current primary research activity is in phrase-based statistical MT and syntax-based statistical MT. Phrase-based models of translation produced better output with less bilingual training data than the word-based models. Phrase-based statistical MT is now the dominant approach in research, and is well supported with academic courses, open-source toolkits, and an online community with the website www.statmt.com. Syntax based statistical MT is the growth area right now, and seeks to address weaknesses of the phrase-based approach in handling complex grammatical structure, and translation between languages with very different basic word order.
The world of MT made some great strides forward in moving to statistical methods. The convenient availability of large quantities of data for the major languages, and the ability to train translation systems automatically has led to rapid system development, and cost effective vocabulary and style adaptation that were expensive and slow with rule-based MT. Statistical models further manage to produce output that is much more fluent sounding than rule-based MT. But don't sell your shares of Systran just yet - rule-based MT, especially as a commercial product, has some advantages that are not eclipsed by statistical MT, particularly for translating into morphologically complex languages, in providing extensive dictionary-based customization capabilities, and providing translation capability for language pairs or text types where no bilingual training data exists. And the rule-based MT developers are not sitting idle during the statistical revolution. Their efforts to hybridize are yielding very interesting results, and have ensured that the " horse race" between the generations of MT is not over yet.
The next paradigm shift
In a second marriage, the early years are spent in happy relief from the problems of the prior marriage. And this is where the research community is with statistical machine translation, happy to be free of the drudgery of manual rule development. And the community of users is also finding that the current advances bring machine translation closer to its potential as a mainstream business tool. But statistical approaches don't solve every problem from the rule-based era, and even introduce some new ones. The hypothesis of another paradigm shift, and new "era" of machine translation 5 or 15 years in the future is my speculation that eventually a researcher, perhaps from another field entirely, will have an "aha" moment that shows the way to the next era of machine translation. And that generation can tackle the problems that still remain on the prior generations' "someday/maybe" project list.
Current focus, next step
Researchers looking for the next increment of improvement in translation accuracy are currently exploring ways to incorporate syntactic information into translation models and language models. This exploration began in about 2003 with some unsuccessful efforts, gradually had some success and has now gained popularity as a research pursuit. In the research tracks at the AMTA and EMNLP (empirical methods in natural language processing) conferences in October 2008, there were 14 papers reporting advances in the phrase-based framework and 10 in various syntax-based frameworks. A recent survey by Dr. Daniel Marcu of USC/ISI and Language Weaver polled his colleagues in the research community about the best and worst ideas in the history of natural language processing<SUP id=2_2>[2]</SUP>. The responses, which also include predictions on what will work well in the future, suggeste that syntax-based methods for statistical MT will continue to be an area of significant focus through about 2013. The same survey suggested that semantics, robust handling of different topics and topic shift, and handling of discourse structure, will begin to see results around 2018.
The National Institute of Standards and Technology (NIST) conducted a series of workshops in 2006 with the prominent researchers in machine translation and natural language processing. They were asked to identify the biggest challenges for the field, and the technological advances necessary to achieve the field's significant long term research goals<SUP id=3_3>[3]</SUP>. One of the long term goals for machine translation was to be able to translate text with roughly the skill of a human. Some researchers believed that in order to do this, computers must be able to "understand" language. That group might put "interlingua", or something like it, again on the top stair step for the statistical era. But many researchers don't buy into the notion that successful translation has to resemble the human translation process, and are wary of a return to the old days of AI, in which pursuit of human-like function was pursued without attention to system performance or scaling up to real world problems.
In the opening paragraph of this article, I emphasized that machine translation translates sentences. A challenge identified by the NIST survey, which has sometimes been brought up by customers, is the inability of current MT systems to consider information from outside the sentence being translated. This emerged as a problem in the rule-based MT era, did not get much attention then, and has not been a topic of much research in the statistical era either. The need to draw on information from outside the sentence was identified in the NIST study as a key enabler for the long term goals of machine translation research. The ability to draw on a larger information resource, whether from the surrounding context, or perhaps world knowledge, could be the innovation that defines the next era of MT research.
When statistical machine translation emerged as an idea, it came from researchers working on speech recognition and signal processing. At the time, this seemed like an absurd leap to the linguistic rule-based MT community. It is conceivable that the next paradigm shift will similarly take the statistical MT research community by surprise.
Meanwhile back in the commercial world
Note that statistical machine translation has reached the deployable stage in two commercially licensable software products (Language Weaver and IBM), one free online service (Google), and one in-house system (Microsoft). A new company, Asia Online appears to be on the point of having statistical MT offerings, and there are probably others that haven't come to my attention yet. But the majority of commercially available MT software that is doing real work out in the world is still linguistic rule-based. Examples include Systran, SDL, LEC, ProMT, Linguatec, WordMagic, Apptek, Sakhr, and many Japanese, Chinese and Korean MT systems that are mostly available in those regions. As I hinted earlier, the rule-based MT developers are starting to get comfortable with statistical thinking, and are finding ways to combine the strengths of the new approaches with the systems and resources they have built up over many decades. And this work in industry is another component of the MT research landscape.
Hybridization
Many observers of the MT community believe that the best results will come from hybridization - the combination of resources and techniques from the rule-based and statistics-based approaches. At least two genuine hybrid approaches have emerged:
- <LI roundtrip="0" lastVisited="0">Sequential hybrid: Joint research between the Language Technologies Research Centre in Canada and Systran software used phrase-based statistical methods to create a statistical postediting module for rule-based MT. Working from French to English, the statistical posteditor was trained to "translate" between Systran's rule-based English output and a polished human English translation. The sequential hybrid outperformed a purely statistical translation system trained on the same data set going from the French source to English. This approach has the important impact of eliminating the "BLEU score gap" between rule-based and statistical machine translation systems, giving fluency to rule-based MT output. One paper reports that a postediting module can be trained with far less data than is required to build a full bilingual SMT system. One of the papers reporting on these results is available here: http://iit-iti.nrc-cnrc.gc.ca/.../NRC-49352.pdf
- All-Resources Hybrid: Apptek, pursuing the vision of CTO Hassan Sawaf, has embarked on a hybrid that is primarily a search process, as in statistical MT, but which makes many of the resources from Apptek's a rule-based systems also available in that search. This means that dictionaries and linguistic rules are available alongside translation model and language model parameters in the translation process. This approach has the handy feature of being able to draw on whatever resources are available - where no corpora are available, it can utilize just rules and dictionaries, and where no rules or dictionaries are available, it can utilize just corpora<SUP id=4_4>[4]</SUP>.
Who's winning?
The adoption of the BLEU metric by researchers and their funders, together the regular public MT evaluations conducted by NIST<SUP id=5_5>[5]</SUP> (the U.S. National Institute of Technology and Standards) have given MT evaluations the flavor of a horserace. Prospective customers of MT may feel they are best served by reviewing these evaluations and see "who won". But the real story is not that simple. The NIST evaluations, and the BLEU-score metric, have been very powerful drivers of progress in the research community, and perhaps even explain some of the growth of the cohort of researchers in this area. But BLEU scores and NIST evaluation results are not necessarily helpful in selecting an MT system. There are several reasons for this.
DARPA's Agenda
First, the vast majority of the evaluations conducted by NIST and DARPA over the past 8 years have been on translation of Arabic and Chinese newswire texts into English. This choice mirrors the military/intelligence challenge that is being targeted with research dollars - the overwhelming volume of foreign language materials that must be scanned - but more on that next month when I talk about U.S. Government use of MT!
Research vs. commercial systems
The MT systems used in the NIST evaluations are not commercially available for sale or for use online. The goal in the competitive evaluations is to achieve the highest evaluation score, and for this, many research groups take rather extreme measures. The test involves translating 1,000 sentences which are issued to the participants and must be returned translated. In 2005, Google's Franz Och reported that for the unrestricted data track, they dedicated one computer to each sentence, and allowed the translation search process to run for a week on each one.
Translation systems that are available commercially or free online, have been heavily optimized for speed and efficiency to produce translations in real time. The path from research advances made in an environment of unrestricted resources, to deployable software, can be as little as 6 months or a year.
BLEU favors phrase-based SMT systems
The BLEU metric, first proposed in 2001 by the IBM statistical MT research group, is an automated measure of similarity between two texts. In this case, it measures the similarity between a machine translated text and a human translated "reference". The similarities it captures are words and word-sequences that appear in both texts. Because human translations often differ from each other in word choice, it is common to use the BLEU score to compare an MT output to 4 reference translations from different human translators. In the early 2000s, BLEU was a blessing. It enabled researchers and their funders to instantly evaluate system performance and progress. And in that early phase of statistical MT research, BLEU scores appeared to correlate strongly with human judgments on translation accuracy.
But as statistical machine translation systems got better, and as BLEU was applied to rule-based systems for comparison, some limitations appeared. As Joe Olive, Program Manager of the DARPA GALE program acknowledged at the AMTA conference in 2006<SUP id=6_6>[6]</SUP>, the BLEU score is "not sensitive to comprehensibility or accuracy" and "favors SMT". This growing awareness motivated the DARPA program to move to a different evaluation metric using human editors. The new metric, called HTER (Human Translation Error Rate) has monolingual editors compare a human reference translation with a machine translated sentence. The editor then makes the smallest number of modifications to get the machine translated sentence to mean the same thing as the human translated sentence without attention to style. Those modifications are counted, and the error rate is the average number of words per hundred that were corrected.
Other vagaries of BLEU
A BLEU score is not a generalized measure of system goodness, but a measure of how well a translation system translated a particular text. This is useful in comparing different MT systems only if, as in the case of NIST, all the translation systems have translated exactly the same text. Performance on other texts may vary significantly.
One to five year outlook
Are we there yet?
This is a very exciting time in machine translation. There is an unprecedented number of energetic, highly qualified and competitive research groups who are also producing deployable machine translation software. Developments in the research arena move pretty quickly into real usable translation systems. And the fact that there are several comparably talented groups means that the competition is intense. This is very good for users and prospective users of machine translation, but it will be worth your while to help the research community to focus on your problems.
Earlier I mentioned some abstract programmatic goals of machine translation research, such as adding semantic processing, and raising BLEU scores on Arabic news translations. But real world applications often require effort on problems that are not salient to the research community. Commercial translation services companies and translation clients might be happy if machine translation could deliver 10% productivity increases every 2-5 years in their operations. The U.S. Marine Corps wants the "Star Trek Universal Translator" for every soldier in the field. It's not clear that semantics or BLEU scores are the pptlimiting factors for either of those applications. User goal needs to be explored with developers and researchers, to make sure that R&D efforts will yield progress in practice. The research world needs input, and funding, to energize them, and attract talent and resources to those areas.
In the U.S., the majority of research funding over the last 8 years has come from DARPA in two 5-year research programs, first TIDES (2000-2005), and then GALE (2006-2010), which is now in its third year. These programs have funded a number of research groups to pursue the intelligence agenda for MT: bring machine translation for key languages - Arabic and Chinese into English - to the level where English speaking analysts can scan and gather information from foreign language news (this is a gross oversimplification of the goals, but it is a reasonable summary of what has been achieved). For Arabic-to-English they have certainly succeeded, and the performance of research MT systems lags only slightly behind human first-draft translations. Chinese has proven much more difficult, and the fact that the research campaigns on Arabic and Chinese have been waged with the same algorithms and the comparable amounts of training data, has demonstrated more powerfully that some language pair directions are much harder than others.
Efforts to deploy machine translation often expose areas where companion technologies or combinations need some research effort. But there is not much funding for technology transition or solutions involving MT, and these areas are weak links in putting machine translation to work.
What can you do affect the process?
Show up
Participate in the conference events of the IAMT (International Association for Machine Translation) regional associations: AMTA (www.amtaweb.org), AAMT (www.aamt.info) and EAMT (www.eamt.org). The associations' founding goal was to bring together users, developers and researchers. This provides a forum where you really can get the attention of researchers and developers to hear about their plans and tell them your needs (without just inviting a barrage of sales information.)
Think through and articulate requirements
The research community can pursue general theoretical goals and advancements, or they can pursue real performance targets and capabilities. Some people (including me) complain that research is overly concerned with abstract performance targets given by DARPA, which may not move the technology toward solving real-world translation problems. But DARPA is one of the few places that have articulated clear goals and problems that the research community can tackle. Prospective users of machine translation often aren't clear about the problem they are trying to solve with automation. And so the market has never sent very clear signals to the research community (or to developers).
Be an objective shopper
If you are intrigued by the details of technology, you may find that some approaches more intellectually appealing. But long term happiness with MT will depend on the technology's ability to perform, and the vendor's commitment to support you. Do a thorough evaluation asking questions like, "How does this system perform on my text now?" and "Can it be brought to the level that I need it?", and "How happy are other customers?"
Put MT to work and give feedback
Become a demanding customer. Machine Translation needs real work in order to continue its progress toward becoming a valuable, trusted, mainstream business tool. When software users get frustrated, they most often complain to colleagues. It is so important to tell software developers what you like and don't like. But be persistent, they may not get it the first time. Your comments to MT developers, research funders, and the groups who do evaluation really can impact the priorities and direction of research.
Closing Thought
This article ended up being difficult to write because there is so much activity, and so many intertwining forces at work on MT research today. I have probably failed to mention your biggest concern, favorite research topic or group, or address the question you consider most obvious and pressing. Please email me gerbl@pacbell.net.
Errata
The URL was omitted from last month's article linking to presentations from the Recipes for Success workshop: http://www.amtaweb.org/AMTA2008.html Scroll down just below the sponsor logos.
Author Bio
Laurie Gerber has worked in the field of machine translation for over 20 years, including system development, research, and [COLOR=blue! important][COLOR=blue! important]business [COLOR=blue! important]development[/COLOR][/COLOR][/COLOR]. Throughout this time, users and usability have been a defining interest. Laurie became an independent consultant in April 2008 in order to help user organizations create successes with machine translation and other language technology.
Laurie has been active in the machine translation professional community since 1992 and is currently treasurer of the Association for Machine Translation in the Americas, and President of the International Association for Machine Translation. http://www.amtaweb.org
Notes
- <LI id=1 roundtrip="0" lastVisited="2">^Bernard Vauquois was an influential leader in MT research in the 1970s at Grenoble University, one of the most important research centers in the rule-based MT era. <LI id=2 roundtrip="0" lastVisited="2">^The summary of findings is accessible in a 1 hour presentation with MS Internet Explorer (not Firefox) at:http://webcasterms2.isi.edu/mediasite/...29c <LI id=3 roundtrip="0" lastVisited="2">^This report is available online at http://www-nlipr.nist.gov/.../MT.web.pdf <LI id=4 roundtrip="0" lastVisited="2">^See Hybrid Machine Translation Applied to Media Monitoring at: http://www.amtaweb.org/papers/4.29_Sawafetal2008.pdf <LI id=5>^http://www.nist.gov/.../mt08_official_results_v0.html
- ^http://www.amtaweb.org/AMTA2006/MT06.ppt
ClientSide News Magazine - www.clientsidenews.com